Go 语言实现——goroutine¶
概述¶
goroutine 是对线程的进一步抽象,就像操作系统的进程调度会将 CPU 时间分配给一个个的进程 or 线程去运行一样,goroutine 的调度器会将操作系统分配给 Go 程序各个线程的 CPU 时间再进一步的细分给一个个的 goroutine 去运行,实现了线程的 multiplexing。
和操作系统的进程调度对 CPU 有完全的控制不一样,goroutine 的调度器调度的线程还受到操作系统的限制:
线程上运行的代码如果调用了系统调用,那么这个线程会被操作系统挂起直到系统调用返回。
线程运行的时间片到了之后,操作系统可能会暂时挂起线程一段时间直到线程下次再被调度到。
Go 是怎么解决这些问题并实现一个高性能的 goroutine 调度器的呢?
首先,为了充分利用多核 CPU,Go 程序会同时有 N(N=CPU 数)个线程在同时运行 goroutine,每个线程有自己的 goroutine 队列,还有一个全局的 goroutine 队列。线程循环的执行自己本地队列里的各个 goroutine,只有本地队列里没有 goroutine 可以执行的时候,才会从全局的 goroutine 队列里取 goroutine,避免每次调度都要加全局锁。
第二,为了解决线程调度在系统调用会被操作系统挂起的问题,Go 在物理线程之上抽象出了一个虚拟线程(类似物理内存和虚拟内存),上面说的线程更准确的说是虚拟线程,如果有 goroutine 陷入系统调用(执行的物理线程被操作系统挂起)太久,那么执行该 goroutine 的虚拟线程会挂起这个 goroutine 并创建新的物理线程来执行该线程中的其他 goroutine。
在 Go 里这三个抽象分别用下面三个结构体来表示:
g: goroutinep: 虚拟线程(个数 = CPU 数)m: 物理线程
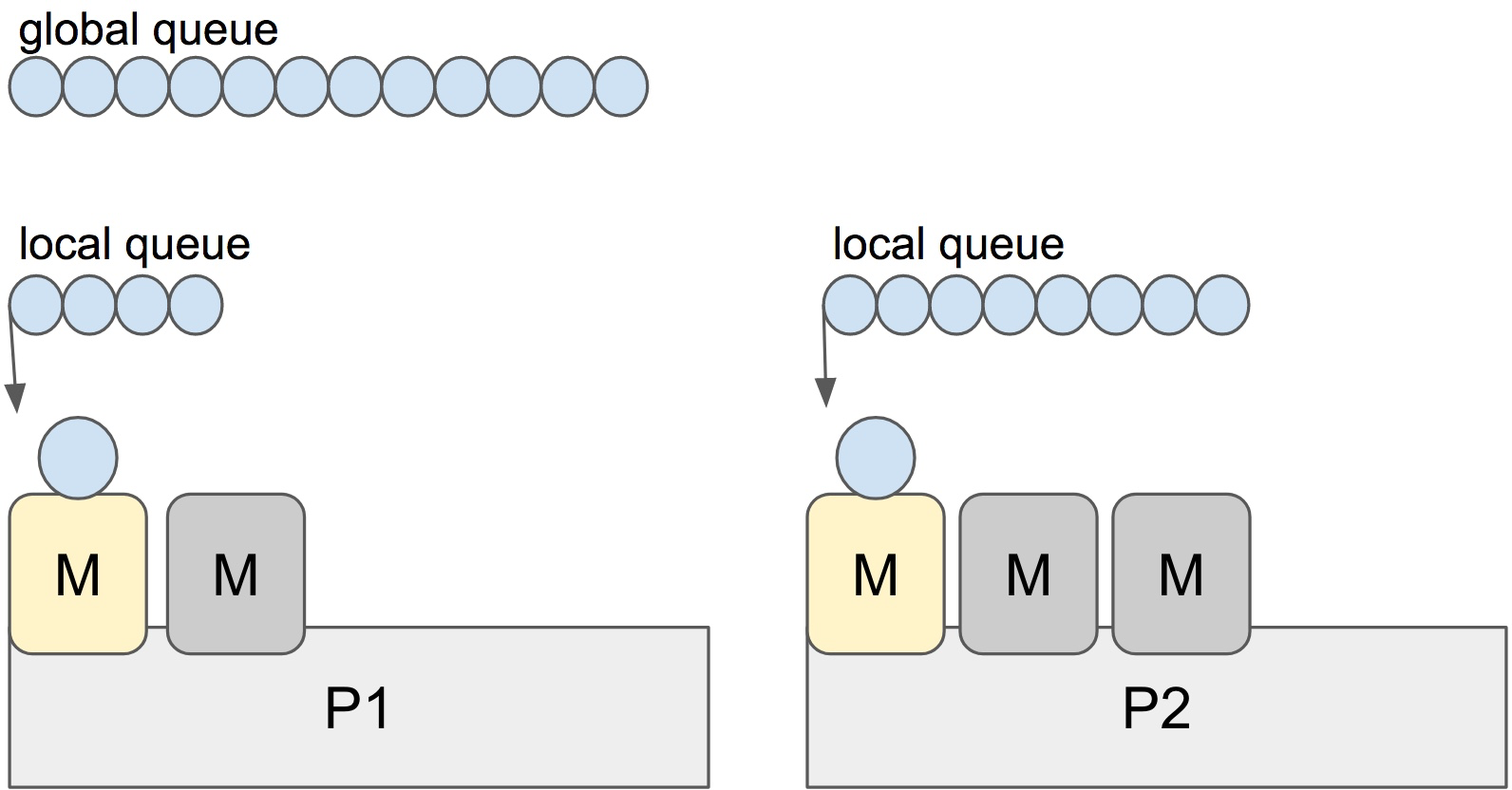
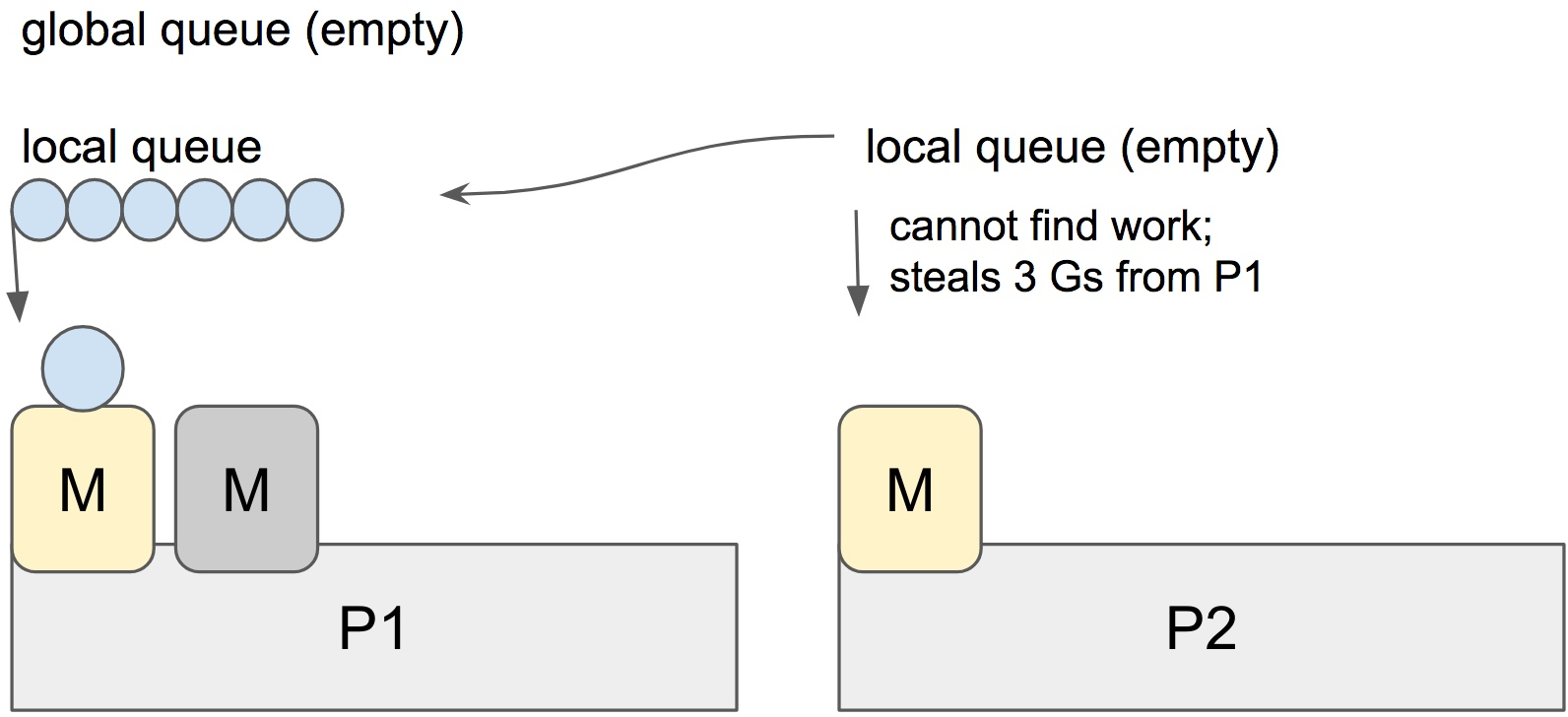
最后,为了平衡线程之间的 goroutine,当线程本地队列里没有可执行的 goroutine 且全局队列为空的时候,当前线程会任意选择一个其它线程,从其线程中 偷(work-stealing) 一半的 goroutine 过来执行。
参考:
Scalable Go Scheduler Design Doc: https://golang.org/s/go11sched
Go’s work-stealing scheduler: https://rakyll.org/scheduler/
创建¶
go func() {
print("hello world")
}()
编译成汇编代码后:
$ go tool compile -l -S test.go
...
// func newproc(siz int32, fn *funcval)
0x001d 00029 (test.go:8) MOVL $0, (SP)
0x0024 00036 (test.go:8) LEAQ "".main.func1·f(SB), AX
0x002b 00043 (test.go:8) MOVQ AX, 8(SP)
0x0030 00048 (test.go:8) PCDATA $0, $0
0x0030 00048 (test.go:8) CALL runtime.newproc(SB)
...
从汇编代码可以看出,go 语句会被转换成下面的函数调用:
runtime.newproc(0, func() {
print("hello world")
})
runtime.newproc 主要做的就是:
准备好新 goroutine 的 g 结构体,将其加入到当前 goroutine 运行在的线程的本地运行队列里去。
因为 goroutine 多了,看看是否还能够再召唤新的虚拟线程 p 出来执行 goroutine,已经饱和了就算了。
// proc.go
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
pc := getcallerpc()
// 切换到当前线程的系统栈(也就是 g0 )去执行 newproc1
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, pc)
})
}
func newproc1(fn *funcval, argp *uint8, narg int32, callerpc uintptr) {
_g_ := getg()
_p_ := _g_.m.p.ptr()
// 从线程本地的 goroutine 队列里取一个空闲的 g 结构体
newg := gfget(_p_)
if newg == nil {
// 本地队列满了的话就新建,_StackMin = 2k
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
}
sp := newg.stack.hi - totalSize
spArg := sp
if narg > 0 {
// 将函数入参从系统中创建者的调用栈中 copy 到新创建的 goroutine 的栈中
memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
}
// newg.sched 这个结构体是 goroutine 切换时用来保存寄存器,栈指针等现场信息的结构体
// 这里伪造在 runtime.goexit 的一开始执行 fn 的现场,这样:
// - goroutine 调度到后恢复现场执行就是开始执行 goroutine
// - goroutine 执行完了会返回 goexit 中执行 goroutine 退出的逻辑(清理啊,调度啊)
memclr(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
// 这个是 runtime.goexit 中的 runtime.goexit1 指令,函数返回后执行的下一条指令
newg.sched.pc = funcPC(goexit) + sys.PCQuantum
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.startpc = fn.fn
// 标示 newg 的状态为 runnable
casgstatus(newg, _Gdead, _Grunnable)
// 将 newg 放到当前线程的执行队列 p.runnext 里。
// goroutine 的运行队列 runq 分为 3 级,p.runnext, p.runq, sched.runq,优先级从高到低。
runqput(_p_, newg, true)
// 如果还有空闲的逻辑线程(刚开始只有一个逻辑线程工作,新建 goroutine 才会新增工作的逻辑线程,直到饱和)
// 并且没有物理线程在 spinning,也就是在寻找空闲逻辑线程(优先复用线程而不是新建)
// 并且当前不是创建 runtime.main 线程(创建 runtime.main goroutine 时,不用管)
// 那么唤醒一个空闲的逻辑线程(可能会创建新的物理线程)出来执行工作
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
}
执行¶
在 golang-internals-bootstrap 中可以看到主线程最后调用了 mstart 函数,这个函数会调度第一个 goroutine 上来执行,也就是 runtime.main 。
func mstart() {
mstart1(0)
}
func mstart1(dummy int32) {
_g_ := getg()
// 将 m 和 p 绑定
if _g_.m != &m0 {
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
// 调度一个 goroutine 过来执行
schedule()
}
func schedule() {
_g_ := getg()
var gp *g
if gp == nil {
// 偶尔从全局 goroutine 队列里取 goroutine,保持一定的公平调度
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
gp = globrunqget(_g_.m.p.ptr(), 1)
}
}
if gp == nil {
// 优先从线程本地队列里取 goroutine
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 本地线程队列里没有 goroutine,从其它队列偷或者从全局队列去
gp, inheritTime = findrunnable()
}
// 恢复调用现场,开始执行 goroutine
execute(gp, inheritTime)
}
在 runtime.main 中 mainStarted 这个变量会设置为 true,告诉 runtime.newproc,之后再创建新 goroutine 的时候,如果虚拟线程未饱和,尝试唤醒,也就是调用 wakep 函数。
func wakep() {
startm(nil, true)
}
func startm(_p_ *p, spinning bool) {
// 取一个空闲的 p,没有的话直接返回
if _p_ == nil {
_p_ = pidleget()
}
// 尝试从空闲线程列表里取一个物理线程 m
mp := mget()
if mp == nil {
var fn func()
// 创建一个新物理线程 m 来运行 p
newm(fn, _p_)
return
}
// 通知找到的空闲线程 m 来运行逻辑线程 p
mp.nextp.set(_p_)
notewakeup(&mp.park)
}
func newm(fn func(), _p_ *p) {
// 申请一个新的 m 结构体并初始化:
// - 调用 mcommoninit()
// - 申请新线程的系统栈 m.g0.stack,默认 8k,后续会传给 clone 的 childstack 参数传给新线程
mp := allocm(_p_, fn)
// 设置该线程 m 执行用来执行逻辑线程 p
mp.nextp.set(_p_)
newm1(mp)
}
func newm1(mp *m) {
newosproc(mp, unsafe.Pointer(mp.g0.stack.hi))
}
func newosproc(mp *m, stk unsafe.Pointer) {
// 在 sys_linux_amd64.s 中定义
// int32 clone(int32 flags, void *stk, M *mp, G *gp, void (*fn)(void))
// 这个函数除了完成系统调用的 clone 功能,还会设置好新的线程的 root goroutine 的执行环境(系统栈、TLS 等)
// 最好跳转到 mstart 函数执行
clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart))
}
wakep 最终可能会创建新的线程出来执行 goroutine,这些新线程的入口函数就是上面主线程最后调用的 mstart 函数。
线程上执行的第一个 goroutine 阻塞、运行时间太长或者退出后会触发 Go 系统代码,从而调度第二个 goroutine 上来运行,如此往复,直到终结。
切换¶
以下条件下 Go 调度器会切换 goroutine:
系统调用。
goroutine 运行的时间太长了。
channel/network/… 阻塞。
前面两个切换和启动过程中创建的 sysmon 这个独立线程执行的代码有关。
func sysmon() {
for {
usleep(delay)
now := nanotime()
retake(now)
}
}
func retake(now int64) uint32 {
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
pd := &_p_.sysmontick
s := _p_.status
if s == _Psyscall {
// 如果 p 陷入系统调用的时间太长(1 sysmon tick,至少 20us),handoffp 也就是让其它线程来执行这个 p。
if atomic.Cas(&_p_.status, s, _Pidle) {
handoffp(_p_)
}
} else if s == _Prunning {
// 如果当前的 goroutine 运行的时间太长,抢占之。
if pd.schedwhen+forcePreemptNS > now {
continue
}
// 设置当前 p 上运行的 goroutine gp.stackguard0 = stackPreempt
// 强制 goroutine 下次函数调用的时候栈空间不够,从而进入系统代码运行以触发切换逻辑
// 如果 goroutine 不调用函数的话,那就没有办法了。
preemptone(_p_)
}
}
}
goroutine 在系统调用前会将运行 goroutine 的线程的状态标记为 _Psyscall ,系统调用返回后,如果线程没有被 retake,goroutine 会直接恢复执行(running),如果被 retake 了,goroutine 会被加入执行队列,等待调度器下次调度执行(runnable)。这些是在系统调用前后的 runtime·entersyscall 和 runtime·exitsyscall 中处理的。
// src/syscall/asm_linux_amd64.s
TEXT ·Syscall(SB),NOSPLIT,$0-56
CALL runtime·entersyscall(SB)
...
SYSCALL
...
CALL runtime·exitsyscall(SB)
RET
channel/network 在阻塞的时候会调用调度器的接口挂起对应的 goroutine,跟操作系统的 IPC 类似。
退出¶
// asm_amd64.s
TEXT runtime·goexit(SB),NOSPLIT,$0-0
BYTE $0x90 // <- goroutine 会伪装成插入到这里被调用的样子
CALL runtime·goexit1(SB) // does not return
// traceback from goexit1 must hit code range of goexit
BYTE $0x90 // NOP
goroutine 执行完 return 会回到 runtime·goexit 函数中,从 CALL runtime.goexit1(SB) 处继续开始执行,goexit1 中会调用 schedule 函数调度下一个 goroutine 过来执行。
func goexit1() {
mcall(goexit0)
}
// goexit continuation on g0.
func goexit0(gp *g) {
_g_ := getg()
casgstatus(gp, _Grunning, _Gdead)
// ... 清理退出的 goroutine 的 G 结构体,将其和其它的 M 结构体等脱钩
// 将 G 结构体放回空闲列表复用
gfput(_g_.m.p.ptr(), gp)
// 调度下一个 goroutine 来执行
schedule()
}
goroutine 栈和系统栈¶
每个 goroutine 都会有自己的代码执行栈 g.stack ,这个栈开始的时候只有 2k ,如果栈空间不够了,Go 会申请一段更大的栈空间,然后将现在的栈的内容拷贝过去,如果堆上有指针指向旧栈上的变量,那么修改这个指针指向新栈,然后继续在新栈中执行,realloc stack 的操作叫做 split stack。
Go 函数一开始一般都会有一段检测是否要 split stack 的代码,如果需要的话会先 split stack 然后再执行函数。
"".main t=1 size=78 args=0x0 locals=0x18
0x0000 00000 (test.go:3) TEXT "".main(SB), $24-0
0x0000 00000 (test.go:3) MOVQ (TLS), CX
// if SP < g.stackguard0 跳转到 0071 去执行
0x0009 00009 (test.go:3) CMPQ SP, 16(CX)
0x000d 00013 (test.go:3) JLS 71
...
0x0047 00071 (test.go:5) NOP
0x0047 00071 (test.go:3) PCDATA $0, $-1
// 调用 runtime.morestack_noctxt split stack
0x0047 00071 (test.go:3) CALL runtime.morestack_noctxt(SB)
// 返回函数开头继续执行
0x004c 00076 (test.go:3) JMP 0
split stack 这个操作本身也需要 Go 代码去完成,这个时候 goroutine 的栈上已经没有栈空间去执行这个函数了,为了解决这个问题,split stack 的代码会切换到线程的系统栈去执行。也就是 g.g0.stack 。同样的为了防止调度之类的系统代码执行的时候 split stack,这些系统代码也是切换到系统栈去执行的。
runtime.Gosched()¶
runtime.Gosched() 做的就是主动放弃 goroutine 本次的运行机会,将自己放到队列后面去,等待下次再被调度到。
// proc.go
func Gosched() {
// mcall 会将当前函数的 pc(mcall 的返回地址), sp 指针保存到 g.sched 中
// 然后执行 gosched_m 函数
// 这样 goroutine 被重新调度执行就等于从 mcall 函数中返回。
mcall(gosched_m)
}
func gosched_m(gp *g) {
goschedImpl(gp)
}
func goschedImpl(gp *g) {
// 将当前 goroutine 设置为 runnable 状态
casgstatus(gp, _Grunning, _Grunnable)
// 将 goroutine 和 m 脱钩
dropg()
// 将 goroutine 放到全局的运行队列中
globrunqput(gp)
// 调度下一个 goroutine 上来执行
schedule()
}